Dissertation Update #4: ThE FinAl
Hi! Thanks for reading the final update of my dissertation study 😆 If you’ve been reading since the first blog post of this series, I hope you enjoyed the ride 🚋 Thanks, OG 😎
Recap
The first post of this series talked about the difficulties of developing a psychological scale, the second post discussed the importance of cognitive interviews, the third post talked about pilot testing a scale, and this post will briefly discuss the ✨final✨ administration and analysis of the scale.
Scale Development
As noted in the first post, my dissertation study focused on developing a scale that measures a psychological trait within middle and high school students. There are certain procedures and steps that must be taken in efforts to ensure a rigorous study and takes years to refine a newly developed scale. However, the final analysis in a scale development study is typically an exploratory factor analysis (EFA) which is conducted to understand the dimensionality of the latent trait you’re attempting to measure. In other words, if we were to draw out a diagram of this latent/psychological trait’s structure, what would it look like? Maybe something like the figure below (just as an example).
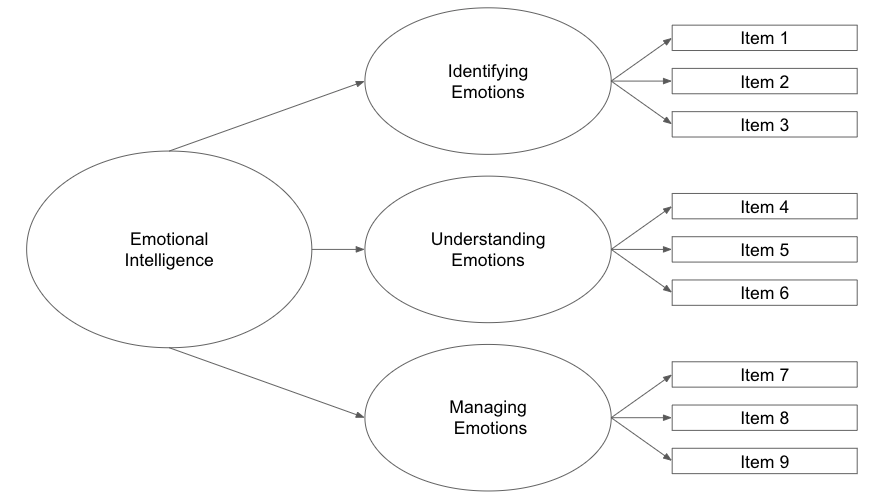
Figure 1: Dimensionality of Example Emotional Intelligence
This is a theoretical figure that I made up for illustration purposes. The idea is that we developed a scale that we believe measures emotional intelligence 💗. When we get to the final step in our scale development process, we conduct an EFA to better understand the dimensionality (or the structure) of emotional intelligence💗. An EFA is an iterative 🔁, model building process with various assumptions and decisions the researcher(s) must carefully consider. For the sake of this example, let’s say figure 1 is the final model the researcher(s) land on. Based off this model, we can see that emotional intelligence 💗 has 3️⃣ sub dimensions (identifying emotions, understanding emotions, and managing emotions). For each of these sub dimensions, the rectangle boxes to the right are the items (or questions) on the scale that measure (or tap into) these sub dimensions. For the record, models will almost never look this clean and orderly in the nascent phase of scale development and their EFAs 🌚
How did yours go, Sarah?
Thanks for asking! 😄 To be honest, it went A LOT better than anticipated. Mainly due to the fact that I ended up with a small(ish) sample size for conducting the EFA. There’s conflicting literature and recommendations about what’s a “good” sample size 👀 (Beavers et al., 2013; Fabrigar et al., 1999; Lawley & Maxwell, 1971; MacCallum et al., 2001). Mine met several recommendations 👍 but, overall, I had less than 3️⃣0️⃣0️⃣ observations.
However, I did conduct three different sensitivity analyses to compare my final model against. And, well, my final model almost exactly matched the final models in the sensitivity analyses process 😎. One technique I used to compare my model against was the regularized exploratory factors analysis (Jung, 2013) which performs better in estimating latent constructs with small sample sizes. This method performs well using a regularized covariance matrix to produce more stable estimates with no risk of model convergence (Jung, 2011). I was able to use this technique in R with the fungible() package 😏
Overall, my final model largely reflected the hypothesized model I developed at the beginning of the study with a few good and helpful surprises/findings. The findings from this study prompt future exploration of the dimensionality and overall understanding of latent trait of interest (which I do intend on further exploring in the near future).
That concludes this series of blogs! Thank you for reading the final blog of the dissertation series 😇 I do hope you enjoyed this fun ride as much as I did! Please stay tuned for my published paper where I can give you more details about the content topic of the study.
Talk to you soon! 💕
Psssssttttttttt….
P.S. My next blog post will be a mini tutorial on information buttons in Shiny apps. Stay tuned if you’re interested 😉
Sarah Narvaiz, PhD
Researcher
My research interests include survey research, psychometrics, and QuantCrit theory.