WOW, I Look Like a Bobblehead: The Ethical Considerations of AI Photo Generation
Read time: 7 minutes
AI software is undoubtedly a global hot topic right now. In late 2022, Pew Research surveyed Americans to understand their awareness and use of AI software and reported that the majority of survey respondents (~55%) said they often interact with AI tools. In the same survey, approximately 38% of respondents reported being more “concerned than excited” regarding the proliferation of AI technology in daily life. Beyond mundane consumers, there are concerns amongst experts regarding the ethical design of AI tools and technologies.
Cue Sarah’s Admission of Skepticism
Well the subheader says it all. I am skeptical of AI tools and technologies with regards to data ethics. Before going any further, it might be helpful to understand what AI is since I think we (average Americans) use it pedestrianly.
Artificial Intelligence: It’s Training Day
My favorite (and most direct) explanation of AI comes from NetApp: “Artificial intelligence (AI) is the basis for mimicking human intelligence processes through the creation and application of algorithms built into a dynamic computing environment. Stated simply, AI is trying to make computers think and act like humans.”
Nice.
So you might be wondering how 0s and 1s within AI software tries to imitate human intelligence (if you weren’t wondering, now you are (wink face))? Don’t worry, I got you.
AI uses machine learning (a component of AI) to imitate human intelligence. In a nutshell, machine learning (ML) is algorithms of statistical models that try to make predictions. For example, grammar/writing tools such as Grammarly, uses AI to make grammar and writing style predictions based on the context provided by the writer. This is how Grammarly can suggest the use “are” vs. “is” when the context is appropriate based on the sentence the user has written. Naturally your next question might be “well how does it make these predictions? How does it know?” And that’s a good question, and a simple one to answer: through the use of trained data.
The biggest foundation AI and ML is built upon is large amounts of data provided by the developer who is developing an AI software. The developer tells the AI to make future predictions using patterns and rules given through trained data. This trained data tells the AI algorithms all the rules it should follow when detecting patterns and predictions when it’s deployed out in the wild. In the case of Grammarly, the software was trained on large amounts of written data, and in this data the algorithms were able to detect the pattern of when to use “are” vs “is” based on the preceding word being detected/categorized as singular or plural.
This Sounds Pretty Great, Sarah!
Agreed! AI has the capability to streamline work and conserve resources (time, energy, money, etc.). But many people take AI-generated content as the end-all-be-all when in actuality it can be deeply flawed because it’s trained on data provided by flawed and inherently biased humans.
Ethical Considerations: Data CAN Be Flawed
In the work I engage in as a researcher, data ethics is always top of mind for me, and I am constantly thinking and considering how I can engage with data in ethical ways. Honestly, I think Gillborn, Warmington, and Demack said it the best: “Computer programs, the ‘models’ that they run, and the calculations that they perform, are all products of human labour. Simply because the mechanics of an analysis are performed by a machine does not mean that any biases are automatically stripped from the calculations. On the contrary, not only can computer-generated quantitative analyses embody human biases, such as racism, they also represent the added danger that their assumed objectivity can give the biases enhanced respectability and persuasiveness. Contrary to popular belief, and the assertions of many quantitative researchers, numbers are neither objective nor color-blind” (2018, p.1-2).
My AI Experience: It Turned Me Into a Bobblehead!
During the summer of 2023, I was beginning to transition out of academia and being a PhD student to preparing to start my first professional job post-PhD. My new employer requested a headshot and a short bio to properly introduce me to the rest of the company. The only professional headshot I had at the moment was a headshot from 2018 which was nice and fine but after 5 years and a PhD, I uhhhh, well I look a little different lol. So I wanted a more updated picture to reflect who I am now. I had a family friend who was a photographer and we planned to take outdoor professional headshots, but Texas experienced its hottest summer on record (weeks being over 100 degrees Fahrenheit) so we kept postponing until the weather was more bearable.
Online I kept seeing how Gen Z’ers were using AI software to generate professional looking headshots so I decided to give it a try. I downloaded an app called Remini. I signed up for the week-long free trial with the intention of deleting my subscription immediately after generating a few good headshots (otherwise the subscription is $10 per week if you don’t cancel). The app asks you to provide 10-12 photos of yourself (specific instructions are provided in the types of photos to provide) and then it asks the “vibe” you want your generated photos to look like (they provide the options and examples). It takes about 5-10 minutes for the app to use the information you provided to generate a handful of AI generated photos. And I DID NOT like the results.
Here are some of the photos generated by Remini.

Figure 1: AI Generated Pictures
I wondered why my body looked so small. So I decided to try Remini again and provide different pictures where you can see more of my body frame rather than just my head; hoping it would detect my figure and generate more appropriate photos. So I waited 5-10 minutes for the new batch of pictures and was even more disappointed because the results were basically the same… it made me look like a bobblehead!
The photos Remini generated made me lose all of my muscle mass I’ve taken years to develop. For reference, I am 5’10” and sit around 166lbs, and I’ve always had a bigger frame (bigger hands, bigger feet, hips, shoulders, head, etc. compared to the average woman).
Here’s what I really look like:

Me being me, I shared the results with a few close friends, and I am HERE for it.
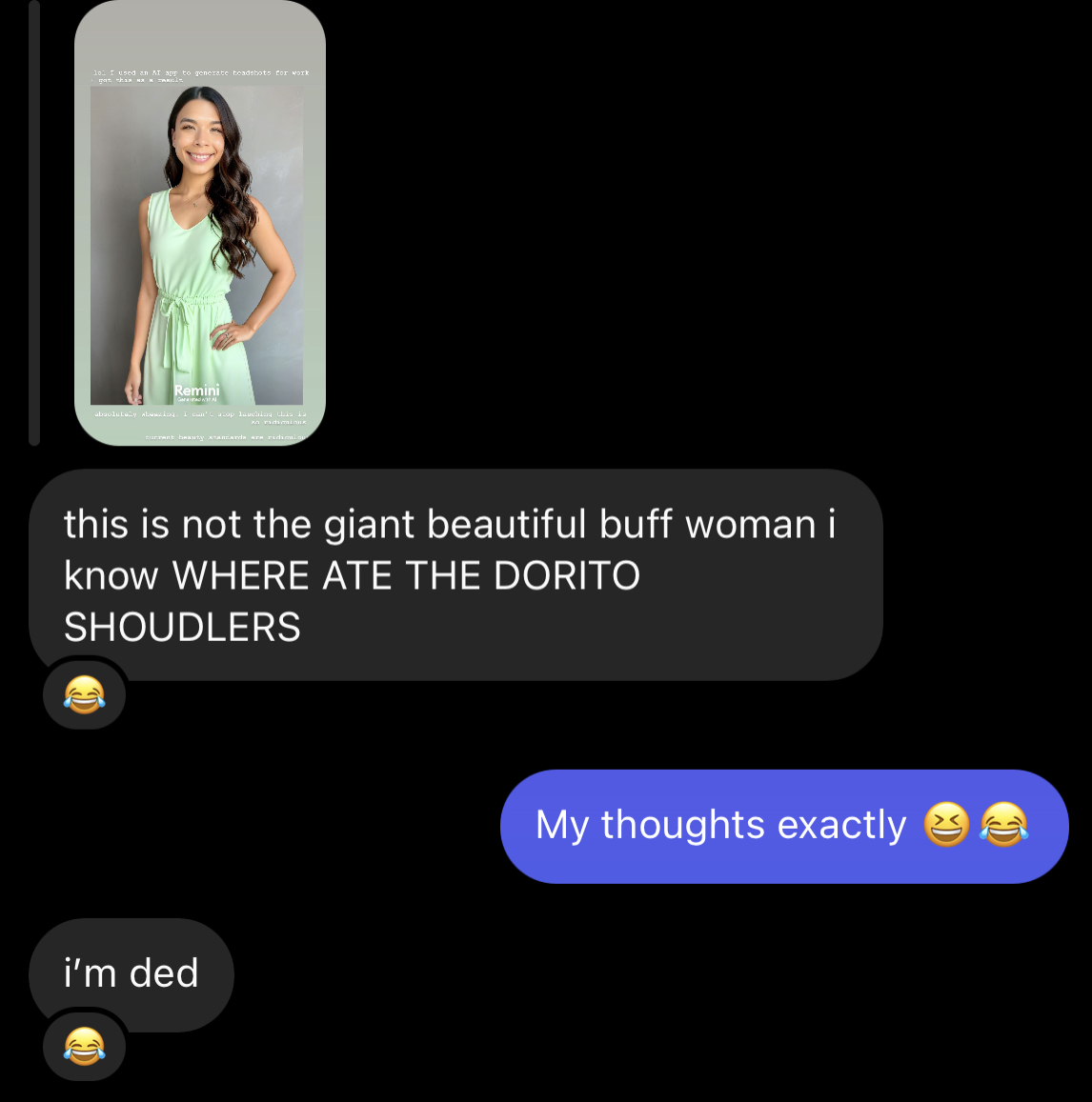
Figure 2: Friend’s Reactions
Data Can Uphold + Perpetuate Harmful Narratives + Ideas
This header says it all, data can uphold and perpetuate harmful narratives and ideas. Why? Because it’s collected, analyzed, and interpreted by humans who are inherently flawed with unintentional (and sometimes intentional) biases. As researchers or consumers of research, we need to critically analyze data and its outcomes.
My question was “Why is Remini producing photos that took away my muscle, that made me physically smaller?” Probably because it was trained on data images that contained a lot of light-skinned females (add in other demographics I’m probably unaware of) who were physically smaller.
Imagine a young female with a similar body type as mine who used Remini to produce AI-generated photos. Is this harming her body image? Will she think she needs to look like this? Will she wish she had smaller hands? Smaller shoulders? What if she avoids resistance training because she’s afraid of “getting too big”? This is the point I am trying to make.
Data is data. It’s not determinate nor definitive.
Sarah Narvaiz, PhD
Researcher
My research interests include survey research, psychometrics, and QuantCrit theory.